
In software development, Agile methodology is the most common project management approach. I would say that Agile principles and DevOps principles have a lot in common, one of them is the culture of collaboration between team members. This may help to build a cross-functional team. Team members will know clearly how to work together and deeply understand the role and responsibilities of each teammate.
That is the reason why I write this article, I share my understanding about DevOps with the aim of building a strong team. I introduce DevOps goals and the key part is metrics to measure the success of adopting DevOps.
DevOps Background
DevOps is a loose set of practices, guidelines, and culture designed to break down silos in IT development, operations, networking, and security.
Articulated by John Willis, Damon Edwards, and Jez Humble, CAMS—which stands for Culture, Automation, Measurement, and Sharing—is a useful acronym for remembering the key points of DevOps philosophy. Sharing and collaboration are at the forefront of this movement. In a DevOps approach, you improve something (often by automating it), measure the results, and share those results with colleagues so the whole organization can improve.
None of the elements in the DevOps philosophy are easily separate from each other, and this essentially by design.
Exploring the goals of DevOps in organizations
The goals of DevOps and what it helps you achieve with your organization is also something that you will get different answers for from different people, depending on their experience, the industry they work in, and how successful those organizations have been at adopting DevOps.
We can define the following common goals of DevOps, there are goals that apply to most organizations.
- Deployment frequency
- Faster time to market
- Lower failure rates
- Shorter lead times
- Improve recovery time
Deployment frequency
We try to design a work well ci/cd process which includes all required jobs and necessary tools to allow developers to check the result of their commit. So the team can focus on their coding and immediately get feedback from the commit, they can quickly update if any changes are needed.
Faster time to market
Most organizations will compete with another for the services they provide. Having a faster time to market gives you a competitive edge over your competitors. With DevOps, We can work to increase value by reducing the amount of time it takes from idea inception to product release.
Lower failure rates
Every organization has failures, but with DevOps, we expect to realize lower failure rates through teams collaborating with each other and communicating better with each other.
DevOps gives teams the ability to work more closely and communicate more effectively. In mature organizations, It allows for cross-functional teams. The shared knowledge between these teams and the individuals within them and the greater understanding of each other’s roles lead to lower failure rates.
Shorter lead times
Lead time is the amount of time between the initiation and completion of a specific task. In DevOps, this would be the amount of time between work starting on a user story and Until that user story is released.
Tied hand in hand with faster time to market, shorter lead times is not just about your product but everything in the whole life cycle. This could be anything from planning where you capture requirements more effectively all the way to building infrastructure quicker than before.
Improved recovery time
Most of the organization, they only focus on commitment with Service-Level Agreements (SLAs). From the DevOps aspect, I strongly believe that how long it takes to recover a service is really important. An organization that measures this metric and takes steps to reduce them is an even more mature organization.
Downtime is lost revenue and reputational damage to your organization, so reducing that level of downtime is very important
I have introduced the DevOps definition and its goals in the business. Next part is the measurement of how successful the DevOps adoption in the organization.
Measuring the success of DevOps
Common metrics used to measure success
Firstly, this part is not aimed at showing how good you are or criticizing how bad you are. The reality is that tracking of performance is a tool for improvement. Continuous improvement (CI) is also a key pillar of DevOps.
Before we look at the metrics for measurement, I would like to define it to three criterias. Each criteria is related to each other. Depending on the size of the team you are running, goals of your organization, you can pick appropriate metrics from each criteria. The number of metrics depends on your goals. Below is the diagram which shows the relation between three criterias.
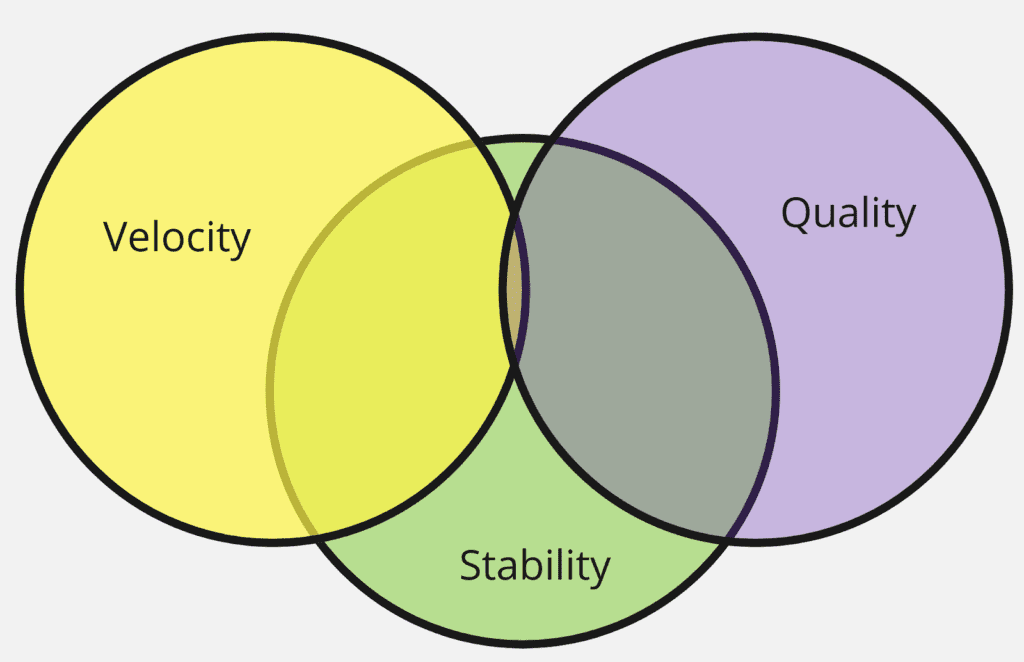
The following possibilities exists in this model:
- Velocity + Stability
- Quality + Stability
- Velocity + Quality + Stability
Stability is core because whatever we are doing with our organization, no matter what changes we make, stability should be made sure to not get any impact from these actions.
Firstly, let’s look at common metrics related to velocity.
Common velocity metrics
Let’s look at some common velocity metrics, as follows:
- Deployment frequency
- Deployment duration
- Change volume
- Test automation coverage
- Lead time
- Cycle time
- Deployment failure rate
- Environment provision time
I will describe these metrics in more detail to let you have more ideas on it.
Deployment frequency
Measure deployment frequency enables you to know how many times the application has been deployed in a specific time period. In mature organizations, the target is to deploy numerous times a day. Normally, this metric is visualized by the CI/CD tool.
Deployment Duration
In case you reuse the build latest artifact, deployment duration is the amount of times it takes to deploy to execute the Continuous deployment (CD). If you want to build a new artifact and deploy it, then record both CI and CD. Most CI/CD tools show the start time and end time of the pipeline, so you can check this metric. The lower deployment duration metric is, the better it is.
Change volume
In DevOps, there is often a common misconception that you don’t follow the normal change management procedures. In reality, it’s quite the opposite—transparency is important, and there is no better tool for transparency in service management than change management. You can measure the number of changes sprint to sprint, or even just monthly, to get an idea of the number of releases you are shipping.
Test automation coverage
Test automation is also a key part of automation in DevOps. When talking about measuring coverage in test automation, we mean the amount of the application or code base that is covered by automated tests.
Lead time
Lead time is the amount of elapsed time between adding an item to the backlog and that item shipping to release. This lets you measure how long it takes on average to take an item from backlog to production.
Cycle time
Very similar to lead time is cycle time. The slight difference in this metric is that rather than measuring from when an item is added to the backlog to when that item is shipped, cycle time looks at the time from when work on that item is started to when it is completed, or shipped.
Deployment failure rate
The percentage of code deployments that caused a failure in production. It is the percentage of code changes that lead to incidents and other production failures. Monitoring system can help with this metric. But recording your deployment failure rate as a percentage is also important. This lets you understand how often your deployments fail. Mature organizations look for a value below 5% for large volumes of deployments.
Environment provisioning time
Next, let’s look at all metrics associated with quality
Common quality metrics
Quality is the second important metric after quality. You can have a high velocity which means you are working at a fast rate, but the quality may suffer, this isn’t the scenario we want.
- Defect density
- Defect aging
- Code quality
- Unit test coverage
- Code vulnerabilities
- Standard violations
- Defect reintroduction rate
Let’s go through detail for each metric.
Defect density
This metric can be measured in different ways. It can be the number of defects detected per line of code, per module, or per 1000 lines of code. It could be a useful metric with sprint planning which is used to estimate the number of defects from sprint to sprint.
Defect aging
It is the period between the time the defect is detected and the time it was resolved. Tracking this metric is important when it comes to technical debt.
Code quality
This metric is the number of violations against code quality, defined by many of the rulesets available for whichever language you are programming in. Based on it, developers may have general information about how efficient, readable, and usable code is.
Unit test coverage
It is the percentage of the application that is covered by unit tests written by developers. In test-driven deployment (TDD) environments where the tests are written before the functional code, organizations look for 80% coverage as an absolute minimum.
Code vulnerabilities
It provides insight into the security quality of the application’s code by indicating how many vulnerabilities are present per unit of code. Tracking this metric then becomes important for ensuring you are following good security practices.
Standards violations
Static analysis tools can look at your source code in detail and highlight areas of code that do not conform to standards. These are generally community-driven or professionally set Standards, some tools also allow you to set your custom rule for standard.
Defect reintroduction rate (defect leakage)
Measuring the number of defects that are reported as breaking other functionality and causing other defects to be raised.
Finally, let’s look at common metrics for stability
Common stability metrics
It is the most important metric. In case your application has poor quality, you lose your customer trust. But your application has poor stability , nobody wants to use your application. Below are common metrics for stability.
- Mean time to Recovery (MTTR)
- Deployment downtime
- Change failure rate
- Incident per deployment
- Unapproved changes
- Number of hotfixes
- Platform availability
Let’s jump into detail for each item
MTTR
MTTR is measured from the time the product or system fails until it is available again. This metric shows how long the DevOps takes on average to recover the product. To me, this is a powerful metric, even more useful than availability.
Deployment downtime
It is the average time the application or product is unavailable during the deployment. It can be measured as percentage of available over the month or print, or measured during a specific block of time.
Change failure rate
It’s important to make use of change management, own your failures, and measure the change failure rate as a percentage of changes implemented. This may be something the change management team already measures.
Incidents per deployment
It is tracking the number of incidents raised per deployment. Based on it, you will have a vision of the percentage of impact to users from each release.
Unapproved changes
It will track the number of unauthorized or unapproved changes on a platform.
Number of hotfixes
Measure the numbers of deployment from hotfixes. Looking to put measures in place to reduce this number is also a key differentiator between immature and mature DevOps organizations
Platform availability
It is one of the important metrics that looks at measuring the availability percentage of your platform.
I have introduced all the metrics that can be used to measure the success of DevOps. Honestly, I feel there are too many metrics to become a “successful DevOps”, so do you think that we need to target to adopt all these metrics for your organization ?
Metrics suitable with the team
As I mentioned before, depending on your goals, your organization vision and your organization type, you will define which criteria you are focused on, and which metrics are necessary. Let’s have a look at these scenarios.
Scenario 1: Small organization with a dedicated DevOps team
For small organizations, It is easier to adopt agile, smaller teams allow for faster feedback loops and cycle time.
For them, It’s important to prioritize stability and quality. So it’s recommended to have below metrics:
- MTTR: Understanding how long it takes to recover the application is critical. It is useful to track which step you take most of the time and optimize it. This information is also useful for architecture improvement to reduce the recovery time.
- Platform availability (> 99%): This information is useful to improve the high availability of the product. Especially, if your organization supplies the hosting service for customers, It’s a useful metric to show for them. To be honest, It is pressure to make a commitment on the metric, we normally focus on what causes the downtime and optimize it.
- Unit test coverage (>80%): Ensuring most of the function has been tested and that code works as expected.
Scenario 2: Medium/large organization with DevOps team
For this type of team, stability as well as quality is important to them on their journey, but understanding velocity is also important. The team needs a broad view of their performance over time so that adjustments can be made. Beside these metrics in Scenario 1, below metrics for velocity should have:
- Lead time: Tracking lead time allows them to understand where time is used,from the allocation of a backlog item to when it is delivered. This helps the team plan better in the future, give appropriate estimates
- Cycle time: Same as lead time, understanding the average time taken from work starting to shipping also gives the team metrics that help them improve their estimation and planning meetings, delivering over time to improve customer satisfaction
- Deployment downtime: DevOps needs to understand the impact of their work during releases. Measuring the downtime of your releases helps you improve the automation process in the future
- Deployment frequency: You can understand how often the deployment is, so you can adjust the build server for example. It is not just a number but also checking the success rate and failed rate.
Conclusion
In this article, I introduce DevOps and the goals of DevOps in the business. So that we can understand the vision and it is better for collaboration in a team.
The second part is measuring the success of DevOps, this part is not the criteria to compare between DevOps. Again, we are working on different products and different goals, so these metrics are good to know which part you should improve and adopt it into your project.
Would you like to read more articles by Tekos’s Team? Everything’s here.