
This article is aiming to save some time and memory for myself (and maybe others) when coding. There will be multiple notes like this in the near future for other topics, such as: Kafka, Clickhouse, Trino, SQLalchemy…
I learned all these notes while working in the data field. It may not be 100% correct, feel free to leave some comments.
What is Kafka?
In short, Kafka is a message cache system, which receives messages, then stores them in a defined period of time, and finally allows the messages to go to different defined places.

Kafka Architecture
More about Kafka basic
Kafka Message Sequence
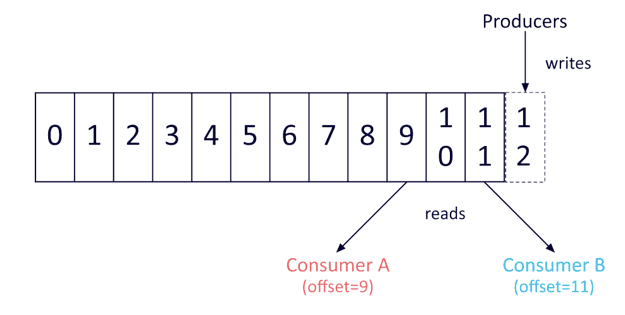
Messages in Kafka are ordered in FIFO
Kafka guarantees the total number of messages produced and consumed. It does not ensure message sequence when topic has multiple partitions.
It will randomly assign messages without keys to partitions. One consumer will be assigned to each partition at a time. The more partitions -> the more consumers can run at 1 time.
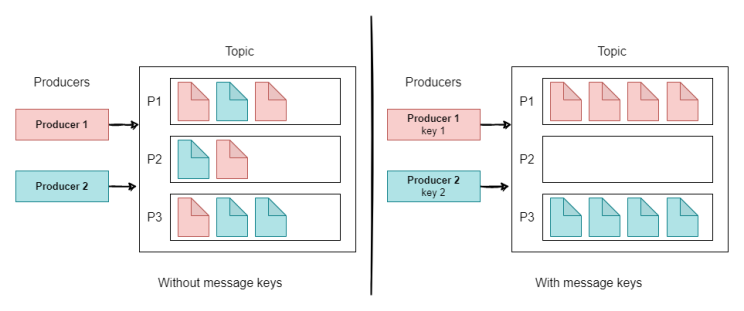
Kafka messages without key got assigned randomly to partitions
To ensure correct message sequence, topic must only contain 1 partition. Then, it will assign each message to a single partition. Consumers will take turns consuming messages from the 1 partition.
While developing a real-time event logging feature, I utilized a caching mechanism to streamline the processing of event logs. Two parallel processing flows were implemented, each storing logs in separate tables. By employing a caching solution, I was able to efficiently handle the relatively small volume of event logs using a single producer and two consumers.
This method is not scalable.
More about how to use multiple partitions in Kafka for logging events:
- https://www.baeldung.com/kafka-message-ordering
- https://engineering.linkedin.com/distributed-systems/log-what-every-software-engineer-should-know-about-real-time-datas-unifying
Small Message Size
You can configure the message size, with a default size of 1 MiB.
The size should be small for fast processing, which will reduce the risk of interruption:
- UI can load and show messages fast.
- Producer can send, and the consumer can receive messages fast.
Message should be <= 1 MiB.
If you send a file to Kafka, you should convert it to a JSON string format and ensure it fits within a single message (1 MiB). We can split bigger files into multiple parts, with each part representing one message.
This method can speed up the processing message a little. When consuming messages from Kafka in Python, the consumer creates a for-loop that will loop through all available messages 1 by 1. We will process every message in each loop. The bigger the message, the more efficient the processing.
In case of processing row by row is not a problem, ideally 1 message = 1 row.
from kafka import KafkaProducer
from kafka.admin import KafkaAdminClient
import json
import sys
import math
bootstrap_servers = # some IPs
# to check kafka connection
KafkaAdminClient(bootstrap_servers=bootstrap_servers)
# producer does not raise error if kafka is not connected
producer = KafkaProducer(bootstrap_servers=bootstrap_servers,
value_serializer=lambda m: json.dumps(m).encode('utf-8'),
retries=5,
max_request_size=26210000 # max message size 25 MiB
)
# ========================================================
# produce asynchronously with callbacks
# Asynchronous by default
read_file_size = sys.getsizeof(json.dumps(ready_file))
limit_size = 1048576 # 1 MiB
if read_file_size <= limit_size:
# 1 message = 1 file
producer.send(topic_name, ready_file)
else:
# split file into chunks
split_chunks = math.ceil(read_file_size / limit_size)
# rows in 1 chunk
len_ready_file = len(ready_file)
step = math.ceil(len_ready_file / split_chunks)
# 1 message = 1 row
for i in range(0, len_ready_file, step):
file = ready_file[i:i+step]
producer.send(topic_name, file)
# block until all async messages are sent
producer.flush()
More about Kafka “small” things
Kafka Consumer Manual Commit
Kafka consumers always automatically commit offsets, meaning that the consumer’s message offset number is updated as soon as a new message consumption loop begins.
enable_auto_commit in KafkaConsumer should always be False because it will make consumer message offset updates manually. Manual commit acts as a fail safe when processing Kafka messages.
We will ensure that the message is processed successfully before telling the consumer to go to the next message.
At the end of message processing code, put consumer.commit() to go to the next message in the next loop.
This offset commit strategy is called At-least-once.
from kafka import KafkaConsumer
from kafka.admin import KafkaAdminClient
import json
bootstrap_servers = # some IPs
# Set up consumer
# FIFO json messages consume, auto-commit offsets
# Consumer will run forever after being called
# to check kafka connection
KafkaAdminClient(bootstrap_servers=bootstrap_servers)
# producer does not raise error if kafka is not connected
consumer = KafkaConsumer(topic_name,
group_id=group_id,
bootstrap_servers=bootstrap_servers,
value_deserializer=lambda m: json.loads(m),
auto_offset_reset='smallest', # FIFO consumption
enable_auto_commit=False, # manually commit after processing message, commit = go to next message # https://stackoverflow.com/questions/64129278/best-way-to-manually-commit-after-processing-message-on-kafka
max_partition_fetch_bytes=26210000 # max message size 25 MiB per partition
)
# Consume message
for message in consumer:
# consume 1 message until it is processed successfully, then it will start consuming the next message.
msg_consumed_successful = 0
while msg_consumed_successful == 0:
try:
values = message.value
<Process the message values>
...
# go to next message after the message was processed successfully
consumer.commit()
msg_consumed_successful = 1
except:
# restart while loop to process the message again after 2 minutes.
time.sleep(2*60)
More about Kafka Offset Commit Strategies
Kafka Producer Flush
The producer.flush() method, similar to Kafka consumer commit, ensures all messages are sent to Kafka. This provides a fail-safe mechanism for sending messages.
Our producer will accumulate produced messages into batches before (asynchronously) delivering them to the broker. The batch size and timing will depend on our producer settings. Batching is fundamental to performance.
Would you like to read more articles by Tekos’s Team? Everything’s here.